[2021] Try Impressive Free Latest Microsoft DP-200 Dumps PDF Questions
Do you want to pass the Microsoft DP-200 exam quickly? Want to get free DP-200 exam braindumps? That’s right, we have collected the latest DP-200 exam questions, in PDF or video format, you can get them for free! Want to get comprehensive DP-200 dumps click on https://www.pass4itsure.com/dp-200.html (Latest DP-200 Dumps PDF and VCE).
Study now, Are you ready?
Certifications: Microsoft Role-based
Exam Code: DP-200
Exam Name: Implementing an Azure Data Solution
Authentic Microsoft DP-200 PDF Share
Thanks to feedback from thousands of Microsoft professionals from all over the world, the Microsoft DP-200 dumps pdf is almost the same as the actual Implementing an Azure Data Solution exam project. Not only that, but you will also gain relevant important knowledge, which will make you a Microsoft professional.
Get free Microsoft DP-200 pdf here: https://drive.google.com/file/d/1MdsDECN7dqml2OMJ0XQ-5LaNMQ__ZwXm/view?usp=sharing
Microsoft Role-based DP-200 Exam Questions 1-13
QUESTION 1
The data engineering team manages Azure HDInsight clusters. The team spends a large amount of time creating and
destroying clusters daily because most of the data pipeline process runs in minutes.
You need to implement a solution that deploys multiple HDInsight clusters with minimal effort.
What should you implement?
A. Azure Databricks
B. Azure Traffic Manager
C. Azure Resource Manager templates
D. Ambari web user interface
Correct Answer: C
A Resource Manager template makes it easy to create the following resources for your application in a single,
coordinated operation:
HDInsight clusters and their dependent resources (such as the default storage account).
Other resources (such as Azure SQL Database to use Apache Sqoop).
In the template, you define the resources that are needed for the application. You also specify deployment parameters
to input values for different environments. The template consists of JSON and expressions that you use to construct
values for your deployment.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-create-linux-clusters-arm-templates
QUESTION 2
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake
Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Assign Azure AD security groups to Azure Data Lake Storage.
B. Configure end-user authentication for the Azure Data Lake Storage account.
C. Configure service-to-service authentication for the Azure Data Lake Storage account.
D. Create security groups in Azure Active Directory (Azure AD) and add project members.
E. Configure access control lists (ACL) for the Azure Data Lake Storage account.
Correct Answer: ADE
AD: Create security groups in Azure Active Directory. Assign users or security groups to Data Lake Storage Gen1
accounts.
E: Assign users or security groups as ACLs to the Data Lake Storage Gen1 file system
References: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-secure-data
QUESTION 3
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and
processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to
the answer area and arrange them in the correct order.
Select and Place:

Correct Answer:
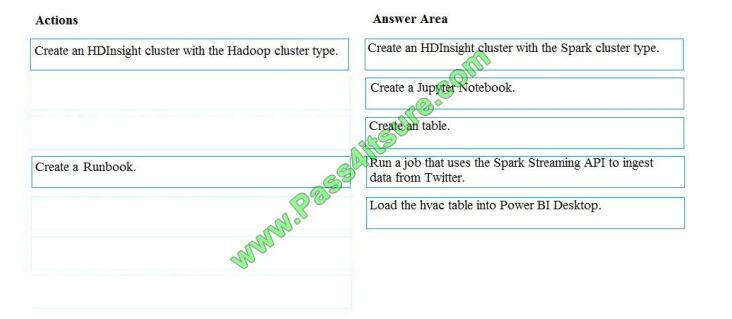
Step 1: Create an HDInisght cluster with the Spark cluster type
Step 2: Create a Jyputer Notebook
Step 3: Create a table
The Jupyter Notebook that you created in the previous step includes code to create an hvac table.
Step 4: Run a job that uses the Spark Streaming API to ingest data from Twitter
Step 5: Load the hvac table into Power BI Desktop
You use Power BI to create visualizations, reports, and dashboards from the Spark cluster data.
References:
https://acadgild.com/blog/streaming-twitter-data-using-spark
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-use-with-data-lake-store
QUESTION 4
You develop data engineering solutions for a company. The company has on-premises Microsoft SQL Server databases
at multiple locations.
The company must integrate data with Microsoft Power BI and Microsoft Azure Logic Apps. The solution must avoid
single points of failure during connection and transfer to the cloud. The solution must also minimize latency.
You need to secure the transfer of data between on-premises databases and Microsoft Azure.
What should you do?
A. Install a standalone on-premises Azure data gateway at each location
B. Install an on-premises data gateway in personal mode at each location
C. Install an Azure on-premises data gateway at the primary location
D. Install an Azure on-premises data gateway as a cluster at each location
Correct Answer: D
You can create high availability clusters of On-premises data gateway installations, to ensure your organization can
access on-premises data resources used in Power BI reports and dashboards. Such clusters allow gateway
administrators to group gateways to avoid single points of failure in accessing on-premises data resources. The Power
BI service always uses the primary gateway in the cluster, unless it\\’s not available. In that case, the service switches to
the next gateway in the cluster, and so on.
References: https://docs.microsoft.com/en-us/power-bi/service-gateway-high-availability-clusters
QUESTION 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You need setup monitoring for tiers 6 through 8.
What should you configure?
A. extended events for average storage percentage that emails data engineers
B. an alert rule to monitor CPU percentage in databases that emails data engineers
C. an alert rule to monitor CPU percentage in elastic pools that emails data engineers
D. an alert rule to monitor storage percentage in databases that emails data engineers
E. an alert rule to monitor storage percentage in elastic pools that emails data engineers
Correct Answer: E
Scenario:
Tiers 6 through 8 must have unexpected resource storage usage immediately reported to data engineers.
Tier 3 and Tier 6 through Tier 8 applications must use database density on the same server and Elastic pools in a costeffective manner.
QUESTION 6
You need to ensure polling data security requirements are met.
Which security technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
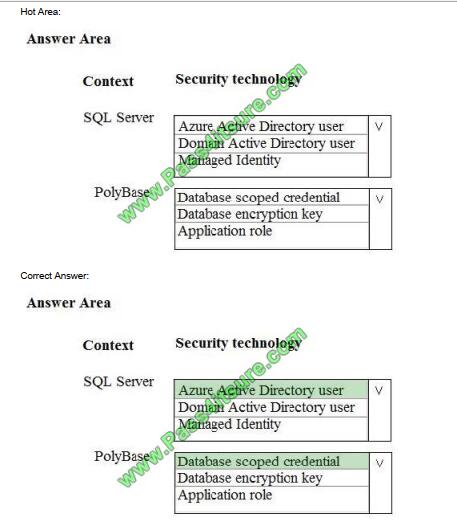
Box 1: Azure Active Directory user
Scenario:
Access to polling data must set on a per-active directory user basis
Box 2: DataBase Scoped Credential
SQL Server uses a database scoped credential to access non-public Azure blob storage or Kerberos-secured Hadoop
clusters with PolyBase.
PolyBase cannot authenticate by using Azure AD authentication.
References:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-database-scoped-credential-transact-sq
QUESTION 7
You plan to create a dimension table in Azure Data Warehouse that will be less than 1 GB.
You need to create the table to meet the following requirements:
Provide the fastest query time.
Minimize data movement.
Which type of table should you use?
A. hash distributed
B. heap
C. replicated
D. round-robin
Correct Answer: D
Usually common dimension tables or tables that doesn\\’t distribute evenly are good candidates for round-robin
distributed table.
Note: Dimension tables or other lookup tables in a schema can usually be stored as round-robin tables. Usually these
tables connect to more than one fact tables and optimizing for one join may not be the best idea. Also usually dimension
tables are smaller which can leave some distributions empty when hash distributed. Round-robin by definition
guarantees a uniform data distribution.
References: https://blogs.msdn.microsoft.com/sqlcat/2015/08/11/choosing-hash-distributed-table-vs-round-robindistributed-table-in-azure-sql-dw-service/
QUESTION 8
You plan to deploy an Azure Cosmos DB database that supports multi-master replication.
You need to select a consistency level for the database to meet the following requirements:
Provide a recovery point objective (RPO) of less than 15 minutes.
Provide a recovery time objective (RTO) of zero minutes.
What are three possible consistency levels that you can select? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Strong
B. Bounded Staleness
C. Eventual
D. Session
E. Consistent Prefix
Correct Answer: CDE
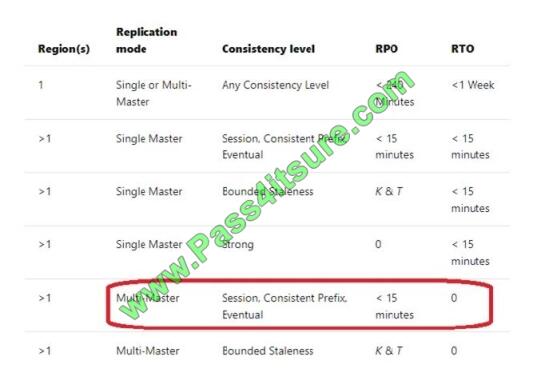
References: https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels-choosing
QUESTION 9
You develop data engineering solutions for a company.
You must integrate the company\\’s on-premises Microsoft SQL Server data with Microsoft Azure SQL Database. Data
must be transformed incrementally.
You need to implement the data integration solution.
Which tool should you use to configure a pipeline to copy data?
A. Use the Copy Data tool with Blob storage linked service as the source
B. Use Azure PowerShell with SQL Server linked service as a source
C. Use Azure Data Factory UI with Blob storage linked service as a source
D. Use the .NET Data Factory API with Blob storage linked service as the source
Correct Answer: C
The Integration Runtime is a customer managed data integration infrastructure used by Azure Data Factory to provide
data integration capabilities across different network environments. A linked service defines the information needed for
Azure Data Factory to connect to a data resource. We have three resources in this scenario for which linked services
are needed: On-premises SQL Server Azure Blob Storage Azure SQL database
Note: Azure Data Factory is a fully managed cloud-based data integration service that orchestrates and automates the
movement and transformation of data. The key concept in the ADF model is pipeline. A pipeline is a logical grouping of
Activities, each of which defines the actions to perform on the data contained in Datasets. Linked services are used to
define the information needed for Data Factory to connect to the data resources.
References: https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/move-sql-azure-adf
QUESTION 10
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior.
You need to implement logging.
Solution: Configure Azure Data Lake Storage diagnostics to store logs and metrics in a storage account.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
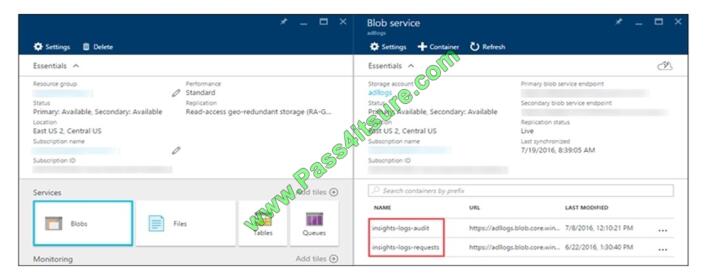
From the Azure Storage account that contains log data, open the Azure Storage account blade associated with Data
Lake Storage Gen1 for logging, and then click Blobs. The Blob service blade lists two containers.
References: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-diagnostic-logs
QUESTION 11
You are developing a solution to visualize multiple terabytes of geospatial data.
The solution has the following requirements:
– Data must be encrypted.
– Data must be accessible by multiple resources on Microsoft Azure.
You need to provision storage for the solution.
Which four actions should you perform in sequence? To answer, move the appropriate action from the list of
actions to the answer area and arrange them in the correct order.
Select and Place:

QUESTION 12
A company plans to use Azure SQL Database to support a mission-critical application.
The application must be highly available without performance degradation during maintenance windows.
You need to implement the solution.
Which three technologies should you implement? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Premium service tier
B. Virtual machine Scale Sets
C. Basic service tier
D. SQL Data Sync
E. Always On availability groups
F. Zone-redundant configuration
Correct Answer: AEF
A: Premium/business critical service tier model that is based on a cluster of database engine processes. This
architectural model relies on a fact that there is always a quorum of available database engine nodes and has minimal
performance impact on your workload even during maintenance activities.
E: In the premium model, Azure SQL database integrates compute and storage on the single node. High availability in
this architectural model is achieved by replication of compute (SQL Server Database Engine process) and storage
(locally attached SSD) deployed in 4-node cluster, using technology similar to SQL Server Always On Availability
Groups.
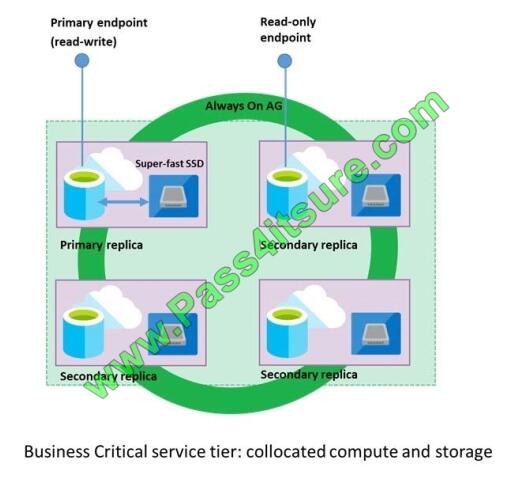
F: Zone redundant configuration By default, the quorum-set replicas for the local storage configurations are created in
the same datacenter. With the introduction of Azure Availability Zones, you have the ability to place the different replicas
in the quorum-sets to different availability zones in the same region. To eliminate a single point of failure, the control ring
is also duplicated across multiple zones as three gateway rings (GW).
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-high-availability
QUESTION 13
You are creating a new notebook in Azure Databricks that will support R as the primary language but will also support
Scola and SQL. Which switch should you use to switch between languages?
A. %
B. \\[]
C. \\()
D. @
Correct Answer: A
You can override the primary language by specifying the language magic command % at the beginning of a cell. The
supported magic commands are: %python, %r, %scala, and %sql.
References: https://docs.databricks.com/user-guide/notebooks/notebook-use.html#mix-languages
DP-200 Implementing an Azure Data Solution Tips

The Pass4itsure high-quality and accurate DP-200 exam dumps creates an atmosphere close to reality and can enhance your confidence in the Microsoft real exam.
Pass4itsure Microsoft exam discount code 2021
Pass4itsure share the latest Microsoft exam discount code “Microsoft“

free Microsoft DP-200 dumps pdf https://drive.google.com/file/d/1iriGqEciNB3eT930AoTl0whsCyu4_Or1/view?usp=sharing
Conclusion:
Exam Preparation is half the battle, and your Microsoft DP-200 exam practice questions materials will bring out the warrior in you. Select https://www.pass4itsure.com/dp-200.html complete Microsoft DP-200 dumps can help you pass the exam!